The GROUP BY clause groups together rows in a table with non-distinct values for the expression in the GROUP BY clause. For multiple rows in the source table with non-distinct values for expression, theGROUP BY clause produces a single combined row. GROUP BY is commonly used when aggregate functions are present in the SELECT list, or to eliminate redundancy in the output. Any data column that may be NULL should never be used as a link in an inner join, unless the intended result is to eliminate the rows with the NULL value.

If NULL join columns are to be deliberately removed from the result set, an inner join can be faster than an outer join because the table join and filtering is done in a single step. Conversely, an inner join can result in disastrously slow performance or even a server crash when used in a large volume query in combination with database functions in an SQL Where clause. A function in an SQL Where clause can result in the database ignoring relatively compact table indexes.

Table functions are functions that produce a set of rows, made up of either base data types or composite data types . They are used like a table, view, or subquery in the FROM clause of a query. Columns returned by table functions may be included in SELECT, JOIN, or WHEREclauses in the same manner as a table, view, or subquery column.

Impala does not support the NATURAL JOIN operator, again to avoid inconsistent or huge result sets. Natural joins do away with the ON and USING clauses, and instead automatically join on all columns with the same names in the left-hand and right-hand tables. This kind of query is not recommended for rapidly evolving data structures such as are typically used in Hadoop. Thus, Impala does not support the NATURAL JOIN syntax, which can produce different query results as columns are added to or removed from tables.
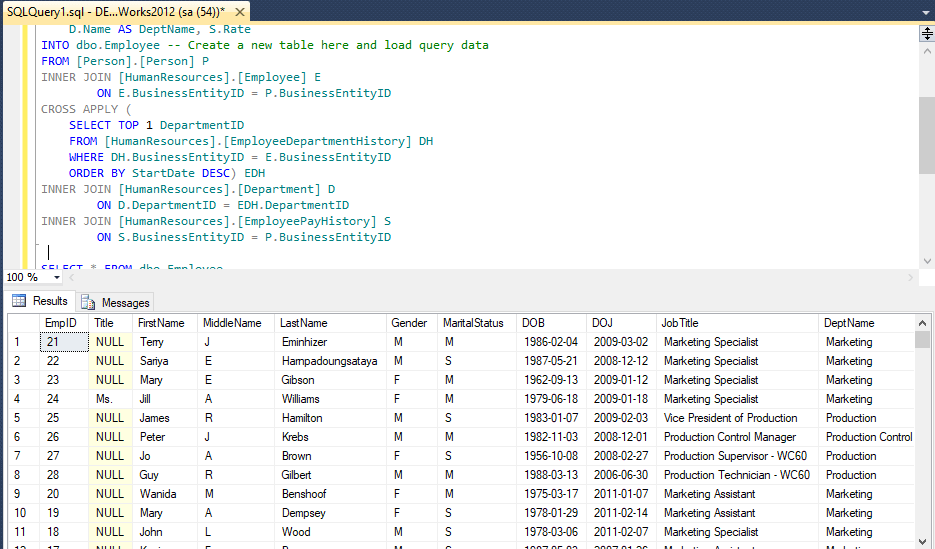
A complex SQL query that includes one or more inner joins and several outer joins has the same risk for NULL values in the inner join link columns. In this example, the columns product_id, p.name, and p.price must be in the GROUP BY clause since they are referenced in the query select list. For each product, the query returns a summary row about all sales of the product.

To better manage this we can alias table and column names to shorten our query. We can also use aliasing to give more context about the query results. SQL Inner Join permits us to use Group by clause along with aggregate functions to group the result set by one or more columns. Group by works conventionally with Inner Join on the final result returned after joining two or more tables. If you are not familiar with Group by clause in SQL, I would suggest going through this to have a quick understanding of this concept.

Below is the code that makes use of Group By clause with the Inner Join. A join query is a SELECT statement that combines data from two or more tables, and returns a result set containing items from some or all of those tables. It is a way to cross-reference and correlate related data that is organized into multiple tables, typically using identifiers that are repeated in each of the joined tables.

The Inner Join can only be safely used in a database that enforces referential integrity or where the join columns are guaranteed not to be NULL. However, transaction databases usually also have desirable join columns that are allowed to be NULL. The choice to use an inner join depends on the database design and data characteristics.

A left outer join can usually be substituted for an inner join when the join columns in one table may contain NULL values. The Join condition returns the matching rows between the tables specifies in the Inner clause. The go to solution for removing duplicate rows from your result sets is to include the distinct keyword in your select statement.

It tells the query engine to remove duplicates to produce a result set in which every row is unique. Using Group By with Inner Join SQL Inner Join permits us to use Group by clause along with aggregate functions to group the result set by one or more columns. The fetch construct cannot be used in queries called using iterate() (though scroll() can be used).

Fetch should also not be used together with impromptu with condition. It is possible to create a cartesian product by join fetching more than one collection in a query, so take care in this case. Join fetching multiple collection roles can produce unexpected results for bag mappings, so user discretion is advised when formulating queries in this case. Finally, note that full join fetch and right join fetchare not meaningful. Conceptually, a full outer join combines the effect of applying both left and right outer joins.
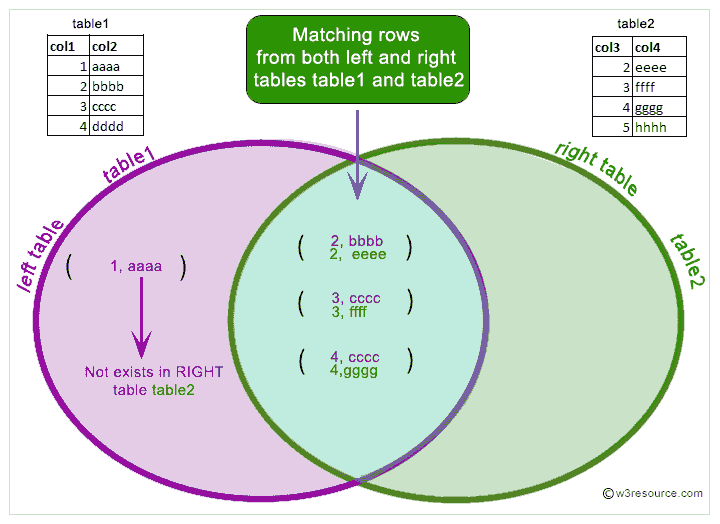
Where rows in the FULL OUTER JOINed tables do not match, the result set will have NULL values for every column of the table that lacks a matching row. For those rows that do match, a single row will be produced in the result set . Inner join creates a new result table by combining column values of two tables based upon the join-predicate.

The query compares each row of A with each row of B to find all pairs of rows that satisfy the join-predicate. When the join-predicate is satisfied by matching non-NULL values, column values for each matched pair of rows of A and B are combined into a result row. ROLLUP is an extension of the GROUP BY clause that creates a group for each of the column expressions.
Additionally, it "rolls up" those results in subtotals followed by a grand total. Under the hood, the ROLLUP function moves from right to left decreasing the number of column expressions that it creates groups and aggregations on. Since the column order affects the ROLLUP output, it can also affect the number of rows returned in the result set. This syntax allows users to perform analysis that requires aggregation on multiple sets of columns in a single query.
Complex grouping operations do not support grouping on expressions composed of input columns. What these queries have in common is that data from multiple rows needs to be combined into a single row. In sql, this can be achieved with "aggregate functions", for which drift has builtin support. Only one instance of each row from the left-hand table is returned, regardless of how many matching rows exist in the right-hand table. An aggregate function takes multiple rows as an input and returns a single value for these rows. Some commonly used aggregate functions are AVG(), COUNT(), MIN(), MAX() and SUM().
For example, the COUNT() function returns the number of rows for each group. The AVG() function returns the average value of all values in the group. The result of a left outer join for tables A and B always contains all rows of the "left" table , even if the join-condition does not find any matching row in the "right" table . This means that if the ON clause matches 0 rows in B , the join will still return a row in the result —but with NULL in each column from B.

A left outer join returns all the values from an inner join plus all values in the left table that do not match to the right table, including rows with NULL values in the link column. Most experts agree that NATURAL JOINs are dangerous and therefore strongly discourage their use. The danger comes from inadvertently adding a new column, named the same as another column in the other table. An existing natural join might then "naturally" use the new column for comparisons, making comparisons/matches using different criteria than before.

Thus an existing query could produce different results, even though the data in the tables have not been changed, but only augmented. Real world databases are commonly designed with foreign key data that is not consistently populated , due to business rules and context. It is common practice to modify column names of similar data in different tables and this lack of rigid consistency relegates natural joins to a theoretical concept for discussion. In the previous tutorial, you learned how to query data from a single table using the SELECT statement.

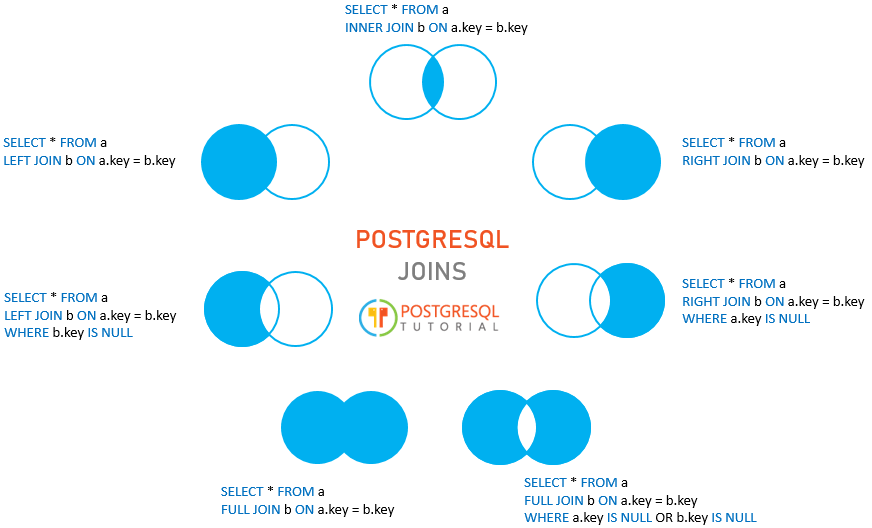
However, you often want to query data from multiple tables to have a complete result set for analysis. To query data from multiple tables you use join statements. An INNER JOIN returns a result set that contains the common elements of the tables, i.e the intersection where they match on the joined condition. INNER JOINs are the most frequently used JOINs; in fact if you don't specify a join type and simply use the JOIN keyword, then PostgreSQL will assume you want an inner join. Our shapes and colors example from earlier used an INNER JOIN in this way. In the result set, the order of columns is the same as the order of their specification by the select expressions.

If a select expression returns multiple columns, they are ordered the same way they were ordered in the source relation or row type expression. Drift supports sql joins to write queries that operate on more than one table. To use that feature, start a select regular select statement with select and then add a list of joins using .join(). For inner and left outer joins, a ON expression needs to be specified. In this syntax, the inner join clause compares each row from the t1 table with every row from the t2 table.
How To Use Group By With Inner Join In Sql The MySQL Inner Join is used to returns only those results from the tables that match the specified condition and hides other rows and columns. MySQL assumes it as a default Join, so it is optional to use the Inner Join keyword with the query. The ORDER BY clause specifies a column or expression as the sort criterion for the result set. If an ORDER BY clause is not present, the order of the results of a query is not defined. Column aliases from a FROM clause or SELECT list are allowed.

If a query contains aliases in the SELECT clause, those aliases override names in the corresponding FROM clause. Rows that do not meet the search condition of the WHERE clause are eliminated from fdt. Just like any other query, the subqueries can employ complex table expressions.

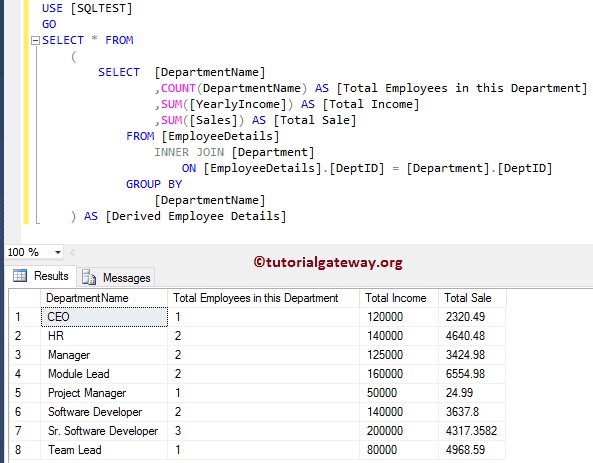
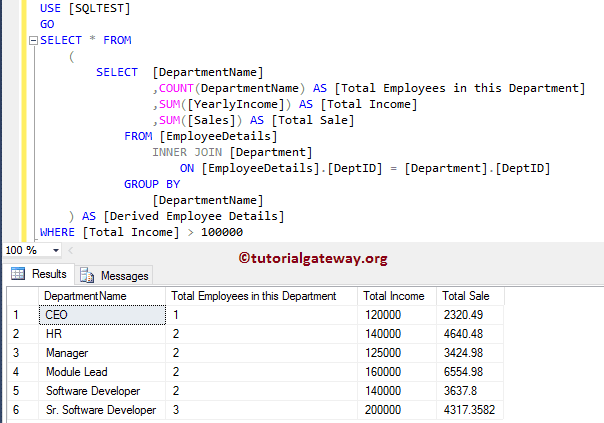
Qualifying c1 as fdt.c1 is only necessary if c1 is also the name of a column in the derived input table of the subquery. But qualifying the column name adds clarity even when it is not needed. This example shows how the column naming scope of an outer query extends into its inner queries. This process continues until the last row of the products table is examined. Adding a HAVING clause after your GROUP BY clause requires that you include any special conditions in both clauses. If the SELECT statement contains an expression, then it follows suit that the GROUP BY and HAVING clauses must contain matching expressions.

It is similar in nature to the "GROUP BY with an EXCEPTION" sample from above. In the next sample code block, we are now referencing the "Sales.SalesOrderHeader" table to return the total from the "TotalDue" column, but only for a particular year. Like most things in SQL/T-SQL, you can always pull your data from multiple tables. Performing this task while including a GROUP BY clause is no different than any other SELECT statement with a GROUP BY clause. The fact that you're pulling the data from two or more tables has no bearing on how this works. In the sample below, we will be working in the AdventureWorks2014 once again as we join the "Person.Address" table with the "Person.BusinessEntityAddress" table.

I have also restricted the sample code to return only the top 10 results for clarity sake in the result set. Athena supports complex aggregations using GROUPING SETS, CUBE and ROLLUP. GROUP BY GROUPING SETS specifies multiple lists of columns to group on.
GROUP BY CUBE generates all possible grouping sets for a given set of columns. GROUP BY ROLLUP generates all possible subtotals for a given set of columns. Assume, we have two tables, Table A and Table B, that we would like to join using SQL Inner Join. The result of this join will be a new result set that returns matching rows in both these tables.

The intersection part in black below shows the data retrieved using Inner Join in SQL Server. You can also include more complex expressions in the query. For each row in the result, those expressions will be evaluated by the database engine. The LEFT or RIGHT keyword is required for this kind of join. For LEFT ANTI JOIN, this clause returns those values from the left-hand table that have no matching value in the right-hand table.
RIGHT ANTI JOIN reverses the comparison and returns values from the right-hand table. You can express this negative relationship either through the ANTI JOIN clause or through a NOT EXISTS operator with a subquery. When selecting groups of rows from the database, we are interested in the characteristics of the groups, not individual rows. Therefore, we often use aggregate functions in conjunction with the GROUP BY clause. Finally, I'd like to add that working with sqlÂaggregate functions – especially when using JOINs – requires you understand SQL and the data you are working with. Try the queries in a smaller subset of your data first to confirm that all calculations are working as expected.
If, possible, check some outputs against a reference value to validate your queries' outcomes. If you're a bit rusty on either subject, I encourage you to review them before continuing this article. That's because we will dig further into aggregate functions by pairing them with JOINs. This duo unleashes the full possibilities of SQL aggregate functions and allows us to perform computations on multiple tables in a single query. Aggregate functions are functions that take a set of rows as input and return a single value.

In SQL we have five aggregate functions which are also called multirow functions as follows. Optionally it is used in conjunction with aggregate functions to produce the resulting group of rows from the database. A subquery with a recursive table reference cannot invoke aggregate functions. A WITH clause contains one or more common table expressions .




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.